Drawing on our extensive experience in building AI-powered enterprise tools, we designed and deployed an on-premise RAG (Retrieval-Augmented Generation) system. This approach allowed us to rapidly launch a pilot solution for live A/B testing with real customer queries.
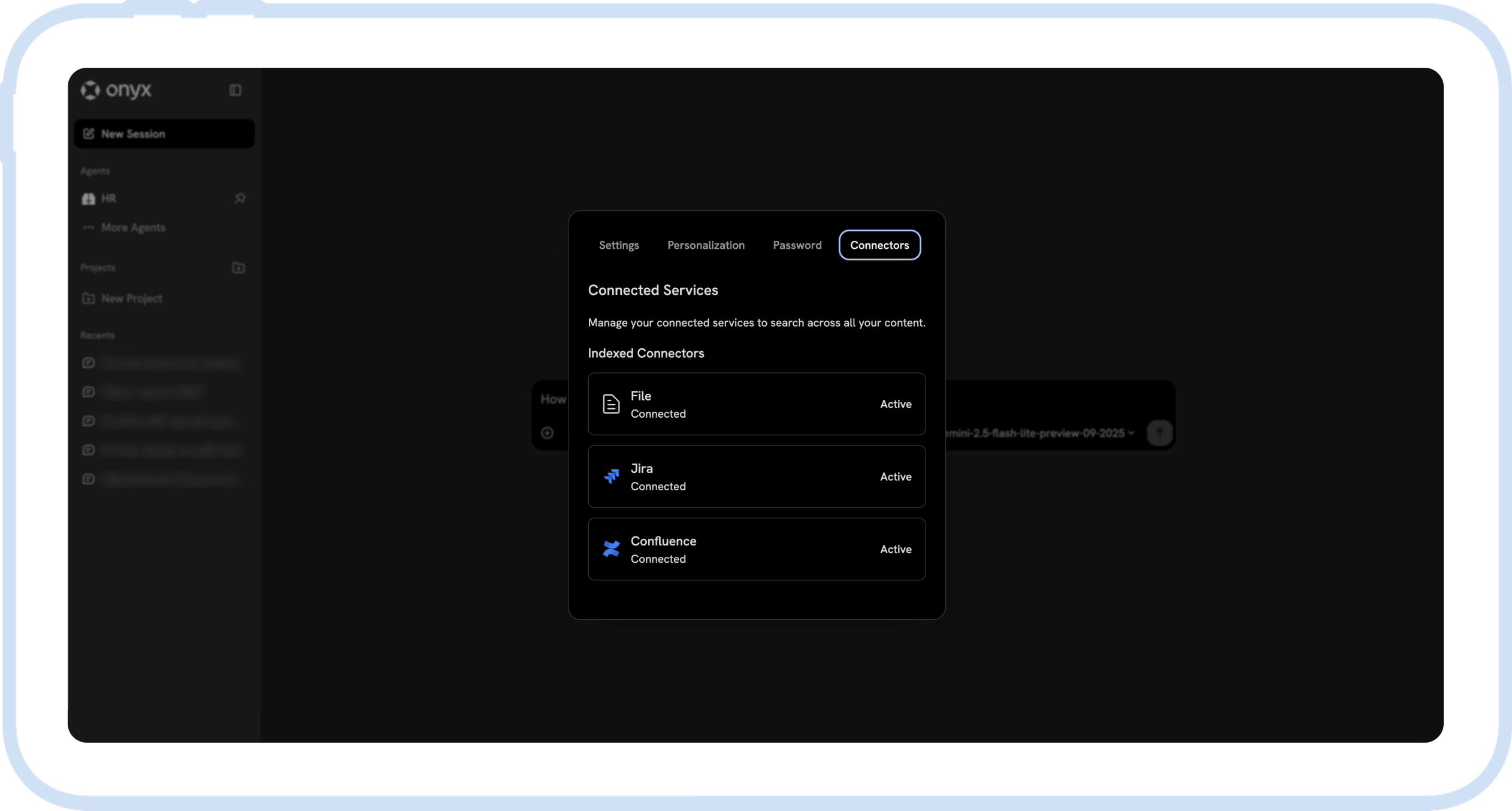
Since internal data security was the client’s absolute priority, using cloud-based AI APIs was out of the question. We configured the entire infrastructure on-premise, directly on the client’s local servers. While this added technical complexity, it guaranteed complete data privacy.
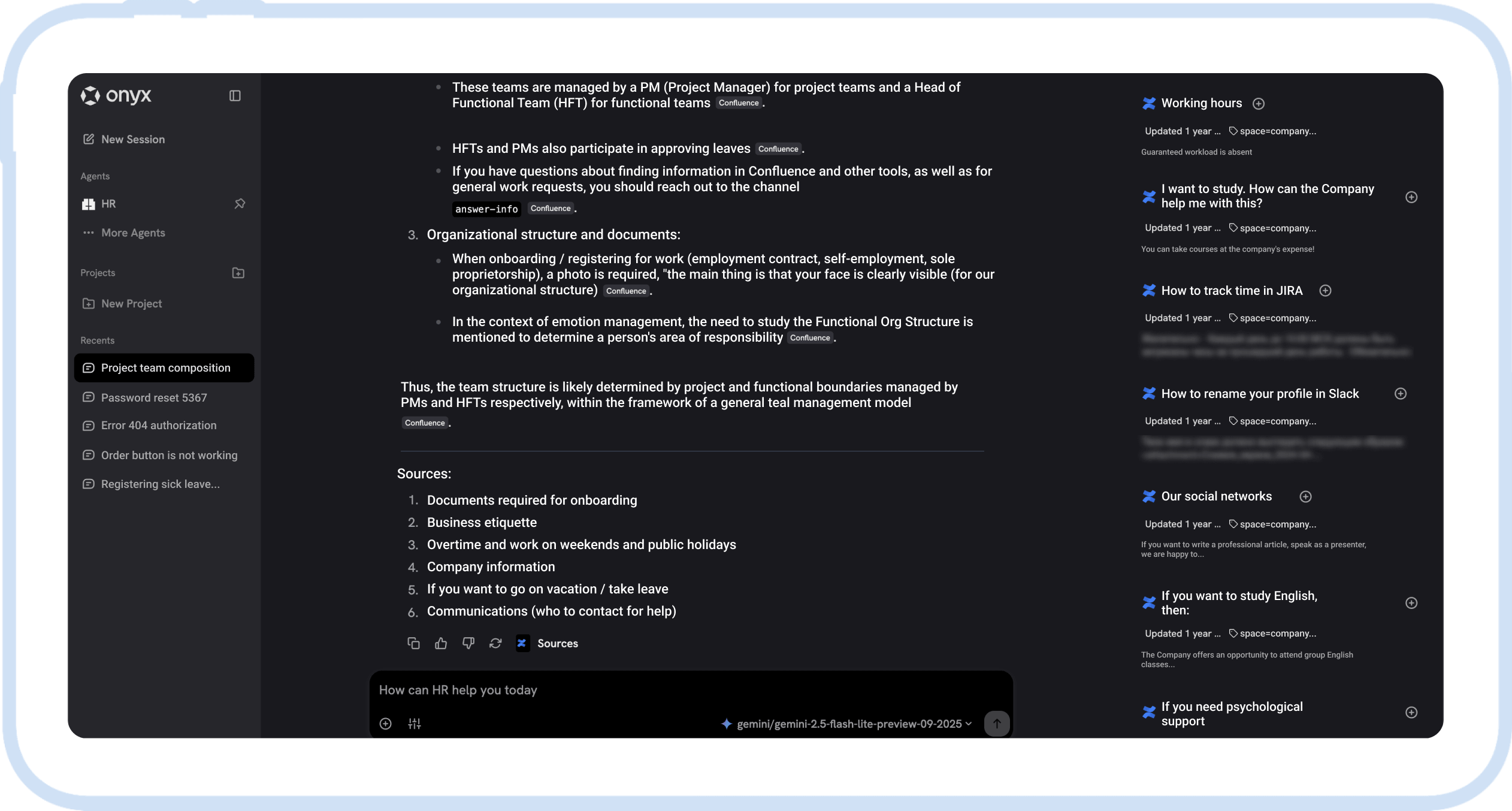
For this local deployment, our team thoroughly analyzed and benchmarked several open-source LLMs. We selected the most stable model meeting all requirements. Our primary criteria included the model’s capacity to handle large volumes of data without losing context (long-context window support), and its speed in retrieving and generating precise, readable answers.
We successfully deployed a robust, enterprise-ready tool on the client’s existing, relatively modest hardware. This optimized architecture demonstrates that even middle-market businesses can implement powerful LLM solutions while keeping infrastructure and maintenance costs low.